信息编码 信息编码共有三种方式,按所携带信息的大小排序可分为:7bit编码、8bit编码、UCS2编码
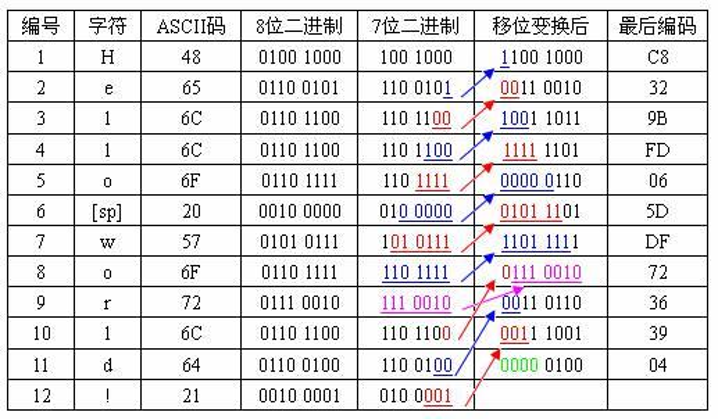
7bit编码 7位编码是种压缩算法,因为,ASCII码(不包括扩展ASCII),其值小于0x80,最高位bit8是0,被忽略了;而7bit编码就利用了这一位来存储数据;其编码时,依次将下一7位编码的后几位逐次移至前面,形成新的8位编码。
根据上图可得到7bit编码解码算法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <stdint.h> #define HIGH_8BIT_MASK(N) (0xFF << (N)) #define LOW_8BIT_MASK(N) (~HIGH_8BIT_MASK(N)) int _7bit_to_asscii(char *p_dst, unsigned char *src, int src_size)int i = 0 ;int n = 0 ;int pos = 0 ;int left = 0 ;char high_part, low_part;8 ;if (src == NULL || p_dst == NULL )return -1 ;8 ) / 7 ;for (i = 0 ; i < n; i++)if (8 == left)7 );1 ;else if (7 == left)8 - left)) >> (8 - left);8 ;else 0 ;8 - left)) >> (8 - left);1 ] & LOW_8BIT_MASK(7 - left)) << left;8 - (7 - left);return n;int asscii_to_7bit (char *p_dst, const char *p_src, int src_size) int i = 0 ;int pos = 0 ;int left = 0 ; int high_part, low_part;char p_usrc[src_size + 1 ];memcpy (p_usrc, p_src, src_size);8 ;for (i = 0 ; i < src_size ; i++){if (left == 8 ){8 - left);7 ;else if (left == 7 ){8 - left);8 ;else { 0 ;8 - left);8 - (7 - left);return ((src_size * 7 + 7 ) / 8 );
8bit编码 8bit编码,顾名思义就是一个char型数据代表一个字符,所以他的编解码是一模一样的,甚至都不叫编解码,直接拿来用即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 int decode_8bit (char *in, int in_length, char *out, int *out_length) int length = 0 ;if (in == NULL || in_length <= 0 || out == NULL || out_length == NULL )return -1 ;for (int index = 0 ; index < in_length; index++)return 0 ;int encode_8bit (char *in, int in_length, char *out, int *out_length) int length = 0 ;if (in == NULL || in_length <= 0 || out == NULL || out_length == NULL )return -1 ;for (int index = 0 ; index < in_length; index++)return 0 ;
UCS2编码 UCS2就是标准的unicode编码, 它是某国际组织设计的一种文字符号编码表,包括了世界上绝大多数文字和符号,包括中文,每个字符使用2字节编码,因此叫ucs2。
对于这种标准编码有现成的函数iconv()可以使用:
1 2 3 4 5 6 7 #include <iconv.h> iconv_t iconv_open (const char *tocode, const char *fromcode) size_t iconv (iconv_t cd, char **inbuf, size_t *inbytesleft, char **outbuf, size_t *outbytesleft) int iconv_close (iconv_t cd)
iconv_open:
tocode:目标编码;fromcode:当前编码;返回值为iconv的句柄
iconv:
cd:iconv_open获取的句柄;inbuf,inbytesleft:输入的字符串及其大小;outbuf,outbytesleft:输出的字符串及其大小
iconv_close:
cd:iconv_open获取的句柄
UCS2编码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 int encode_ucs2 (char *in, int in_length, char *out, int *out_length) iconv_t icon_handler = 0 ;int out_buffer_length = 0 ;char *out_buffer = NULL ;char temp = 0x00 ;if (in == NULL || in_length <= 0 || out == NULL || out_length == NULL )return -1 ;if ((icon_handler = iconv_open("ucs-2" , "utf-8" )) == 0 )return -1 ;if (iconv(icon_handler, &in, (size_t *)&in_length, &out_buffer, (size_t *)&out_buffer_length) == -1 )0 ;printf ("encode_ucs2 errno = %d." , errno);return -1 ;for (int index = 0 ; index < *out_length ; index += 2 )1 ];1 ] = temp;return 0 ;int decode_ucs2 (char *in, int in_length, char *out, int *out_length) iconv_t icon_handler = 0 ;int out_buffer_length = 0 ;char *out_buffer = NULL ;char temp = 0x00 ;if (in == NULL || in_length <= 0 || in_length % 2 != 0 || out == NULL || out_length == NULL )return -1 ;for (int index = 0 ; index < in_length; index += 2 )1 ];1 ] = temp;if ((icon_handler = iconv_open("utf-8" , "ucs-2" )) == 0 )return -1 ;if (iconv(icon_handler, &in, (size_t *)&in_length, &out_buffer, (size_t *)&out_buffer_length) == -1 )0 ;printf ("decode_ucs2 errno = %d." , errno);return -1 ;return 0 ;