最近又遇到了短信编解码的问题,个别符号显示乱码,所以有了这次学习记录。
关于短信PDU编码之前有过详细介绍:sms信息
关于短信内容的三种编码方式也有过介绍:sms信息编码
本次主要学习UTF-8和Unicode码及其互相转换
ASCII码
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符。
我们常说的ASCII 码也就是基础ASCII码,ASCII码表如下:
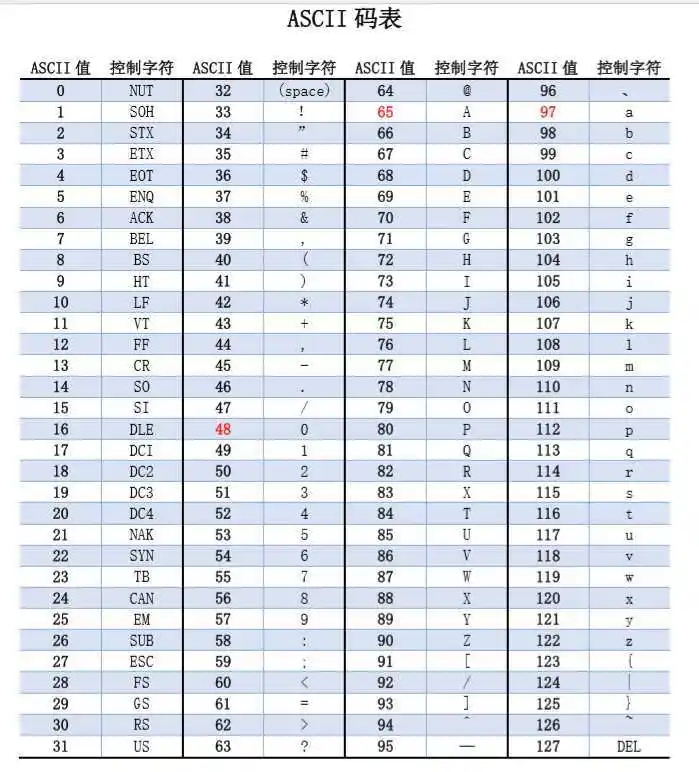
ASCII码有局限性,基础表只能显示现代英语和数字,拓展表每个西欧语言又有不同的规定,再加上最大只能表示256个字符,对于像中文这样有几万个汉字的语言来说,完全不够用。
Unicode码
统一码(Unicode),也叫万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
Unicode通常占两个字节,有一些特殊的拓展会占三个字节。
由于Unicode码只是一个码表,当按照码表储存时,计算机不知道怎么去解析,如有三个字节,那么这是三个ASCII 码还是一个SCII 码和一个Unicode码,又或者是一个三字节的Unicode码.
UTF-8
随着互联网的普及,在数据传输中需要一种统一的编码方式,这时UTF编码出现了,而UTF-8是使用最广的编码方式。值得注意的是UTF-8只是Unicode码的一种表示方式!
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则只有两条:
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围 |
UTF-8编码方式 |
| (十六进制) |
(二进制) |
| 0000 0000-0000 007F |
0xxxxxxx |
| 0000 0080-0000 07FF |
110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
根据这张表我们就可以写出转换函数了
UTF-8转Unicode码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| void utf8_to_unicode(char *in, char *out, int in_len, int *out_len)
{
if (nullptr == in || nullptr == out)
{
return;
}
unsigned char * in_hex = (unsigned char *)in;
unsigned int length = 0;
for (unsigned int index = 0; index < in_len; )
{
if (in_hex[index] < 0x80)
{
out[length + 0] = 0x00;
out[length + 1] = in_hex[index];
index ++;
length += 2;
continue;
}
else if (in_hex[index] < 0xE0)
{
out[length + 0] = (in_hex[index + 0] & 0x1f) >> 2;
out[length + 1] = ((in_hex[index + 0] & 0x03) << 6) | (in_hex[index + 1] & 0x3f) ;
length += 2;
index += 2;
continue;
}
else if (in_hex[index] < 0xF0)
{
out[length + 0] = ((in_hex[index + 0] & 0x0f) << 4) | ((in_hex[index + 1] & 0x3f) >> 2);
out[length + 1] = ((in_hex[index + 1] & 0x03) << 6) | (in_hex[index + 2] & 0x3f) ;
length += 2;
index += 3;
continue;
}
else
{
out[length + 0] = ((in_hex[index + 0] & 0x08) << 2) | ((in_hex[index + 1] & 0x3f) >> 4);
out[length + 1] = ((in_hex[index + 1] & 0x3f) << 4) |((in_hex[index + 2] & 0x3f) >> 2);
out[length + 2] = ((in_hex[index + 2] & 0x3f) << 6) |(in_hex[index + 3] & 0x3f);
length += 3;
index += 4;
continue;
}
}
*out_len = length;
return;
}
|
Unicode码转UTF-8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| int unicode_to_utf8(char *in, unsigned int in_len, char *out, unsigned int *out_len)
{
if (nullptr == in || nullptr == out || in_len % 2 != 0 || nullptr == out_len)
{
return -1;
}
unsigned char *in_hex = (unsigned char *)in;
unsigned int length = 0;
for (unsigned int index = 0; index < in_len; index += 2)
{
if (in_hex[index] == 0x00)
{
out[length++] = in_hex[index + 1] & 0x7f;
continue;
}
out[length + 0] = 0xe0 | (in_hex[index + 0] >> 4);
out[length + 1] = 0x80 | ((in_hex[index + 0] & 0x0f) << 2) | (in_hex[index + 1] >> 6);
out[length + 2] = 0x80 | (in_hex[index + 1] & 0x3f);
length += 3;
}
*out_len = length;
return 0;
}
|