7)head.s
重新设置栈
1 | |
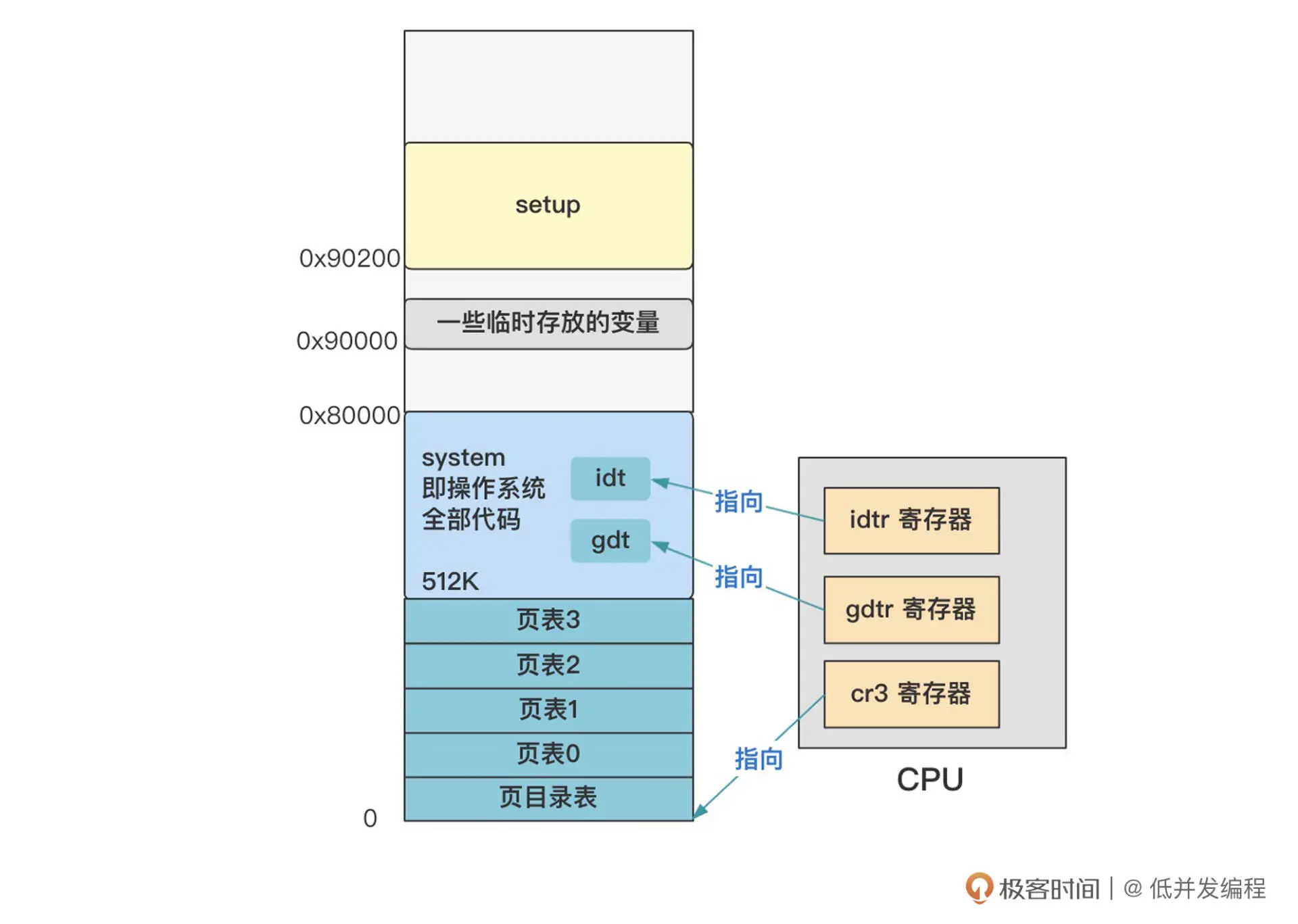
_pg_dir这个表示页目录,之后在设置分页机制时,页目录会存放在这里,也会覆盖这里的代码
- EAX 是一个32位寄存器,能够存储一个32位(4字节)的整数。
- 它可以被分为多个部分进行访问:
- AX:EAX 的低16位。
- AH:AX 的高8位。
- AL:AX 的低8位。
连续五个 mov 操作,分别给 ds、es、fs、gs 这几个段寄存器赋值为 0x10,根据段描述符结构解析,表示这几个段寄存器的值为指向全局描述符表中的第二个段描述符,也就是数据段描述符。
lss 指令相当于让 ss:esp 这个栈顶指针,指向了 _stack_start 这个标号的位置
lss指令:加载段寄存器和堆栈指针。它的全称是 Load Far Pointer to Stack Segment and Stack Pointer。- 语法:
lss destination, source,其中destination是目标寄存器对(通常是esp和ss),source是内存地址。
lss esp, _stack_start 这条指令做以下事情:
- 从
_stack_start地址读取 6 个字节的数据。 - 将这 6 个字节的数据分成两部分:
- 前 4 个字节用于设置
esp(堆栈指针)。 - 后 2 个字节用于设置
ss(堆栈段寄存器)。
- 前 4 个字节用于设置
这个 stack_start 标号定义在了很久之后才会讲到的 sched.c 里
1 | |
因此,lss esp, _stack_start 实际上会:
- 从
stack_start结构体中读取a和b的值。 - 将
stack_start.a的值(即&user_stack[1024])加载到esp中。 - 将
stack_start.b的值(即0x10)加载到ss中。
赋值给 ss 的 0x10 仍然按照保护模式下的段选择子去解读,其指向的是全局描述符表中的第二个段描述符(数据段描述符),段基址是 0。
赋值给 esp 寄存器的就是 user_stack 数组的末端地址,那最终的栈顶地址,也指向了这里,后面的压栈操作,就是往这个新的栈顶地址处压。
设置 idt 和 gdt
1 | |
这里先设置了 idt 和 gdt,然后又重新执行了一遍刚刚执行过的代码。
因为重新设置了idt 和 gdt,这里刷新一次栈,确保栈和段寄存器正确设置,有助于避免潜在的问题。
idt
1 | |
这段代码的主要作用是初始化中断描述符表(IDT),将所有256个中断向量初始化为指向同一个默认中断处理程序 ignore_int,并加载 IDT 描述符,使 CPU 使用新的 IDT。
gdt
1 | |
为什么gdt的第一项为空
捕捉空指针引用
在保护模式下,如果程序试图访问一个无效的段选择子(例如,一个未初始化的选择子),CPU 会引用 GDT 中的第一项(选择子值为 0)。通过将第一项设置为空描述符,可以确保这种访问导致 CPU 触发段错误异常,从而帮助捕捉和调试错误。兼容性要求
根据 x86 体系结构的规范,选择子 0 被保留为空描述符,不能用于有效的段选择。这一要求确保了任何引用选择子 0 的操作都不会导致对有效内存段的访问。简化段管理
在 GDT 中保留一个空描述符简化了段管理。操作系统和编译器可以确保选择子 0 总是无效的,而不需要额外的检查。这种设计减少了出错的可能性,并且使得内存管理更加可靠。历史原因和惯例
这是一个历史遗留的惯例,早期的操作系统和编译器设计者们就开始这样做了。这样做的原因之一是为了向后兼容旧的软件和硬件设计,这些设计假设 GDT 的第一项是一个空描述符。
这里和之前一样,只是大小从8MB变成了16MB,最终设置完成的位置如图:
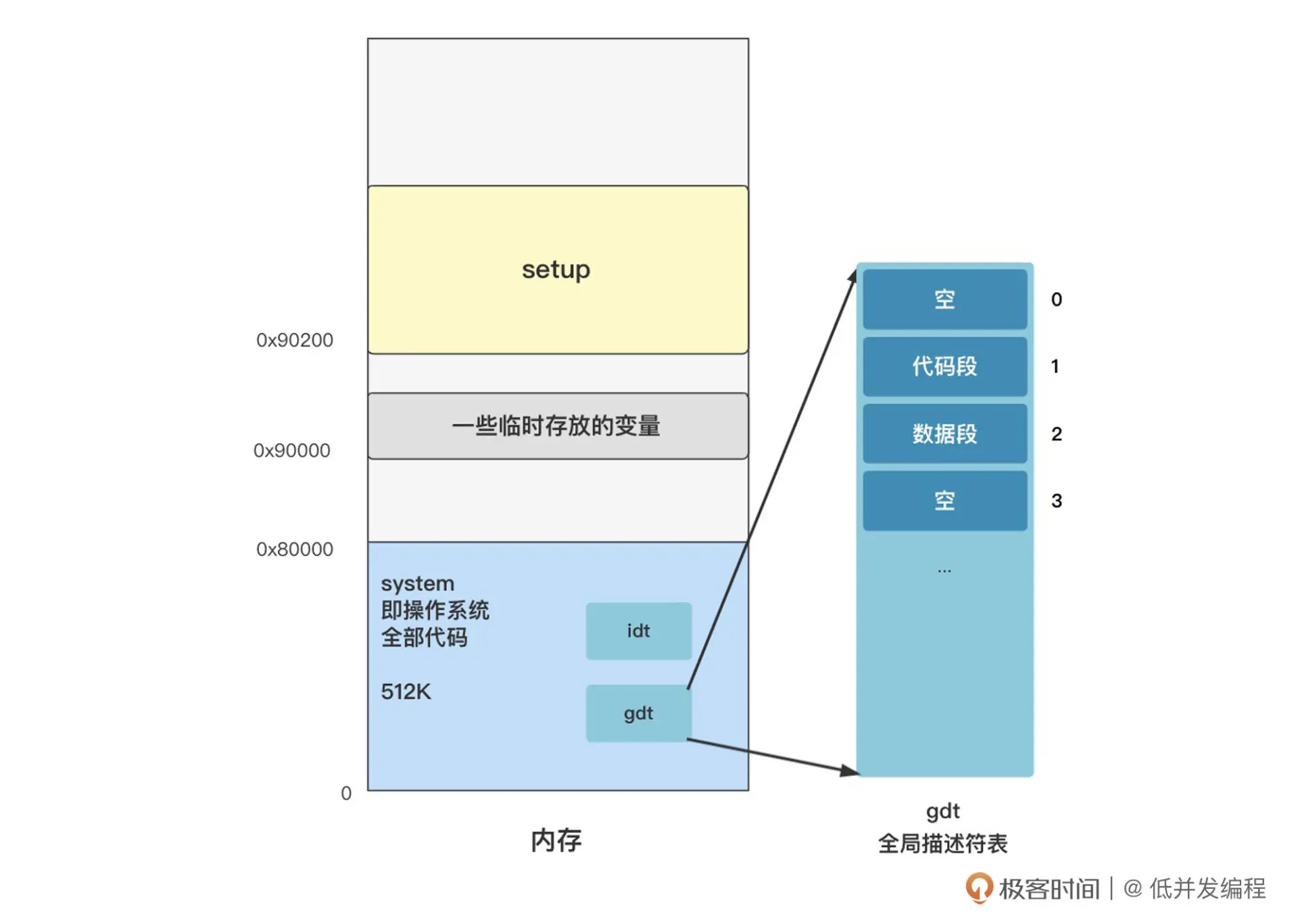
原来设置的 gdt 是在 setup 程序中,之后这个地方要被缓冲区覆盖掉,所以这里重新设置在 head 程序中。这样,这块内存区域之后就不会被其他程序用到并且覆盖了。
分页
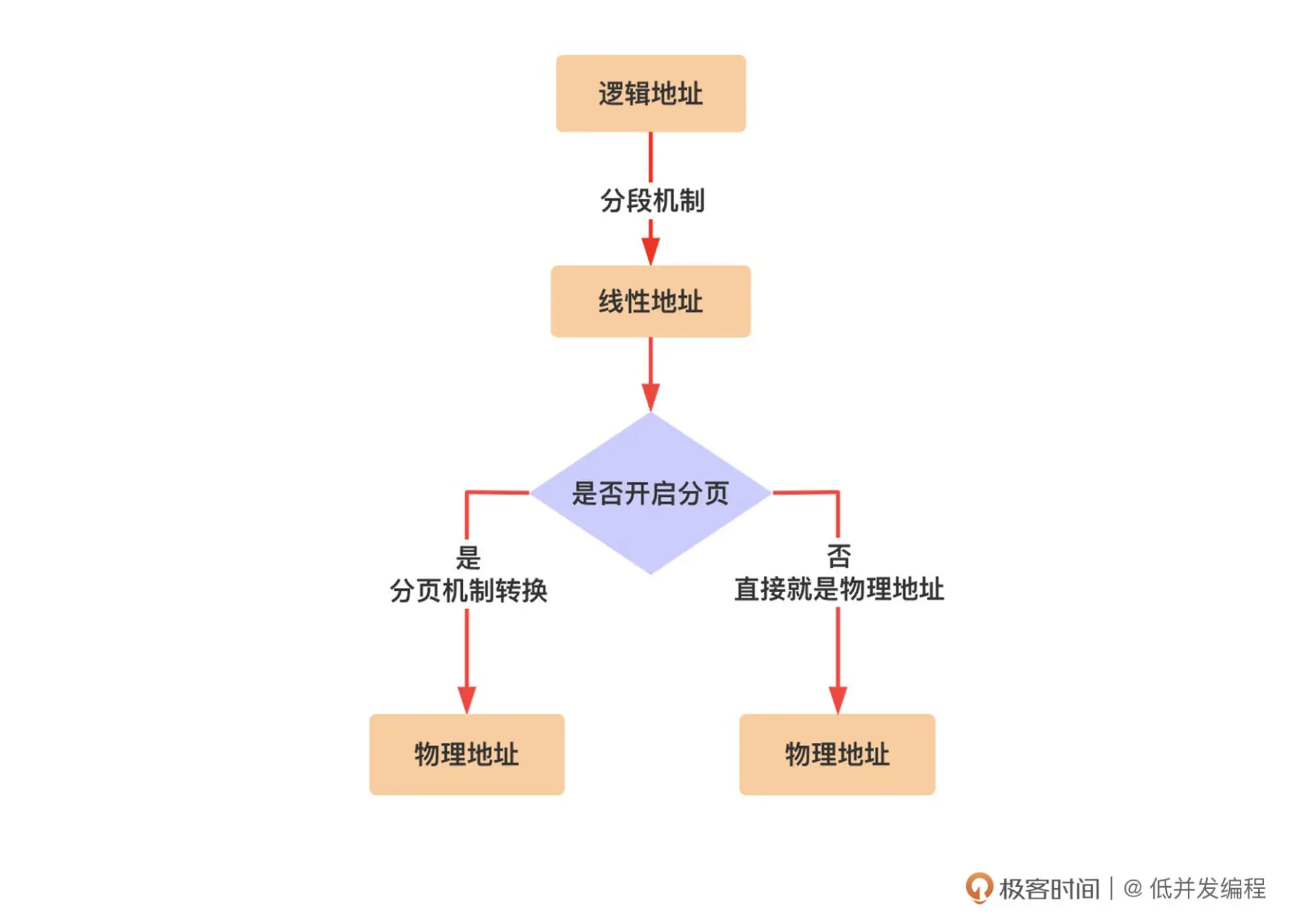
在实模式下物理地址是段地址x16+偏移地址;在保护模式没有开启分页时,物理地址是段基址和偏移地址相加;打开分页后,需要再根据分页机制进行转换:
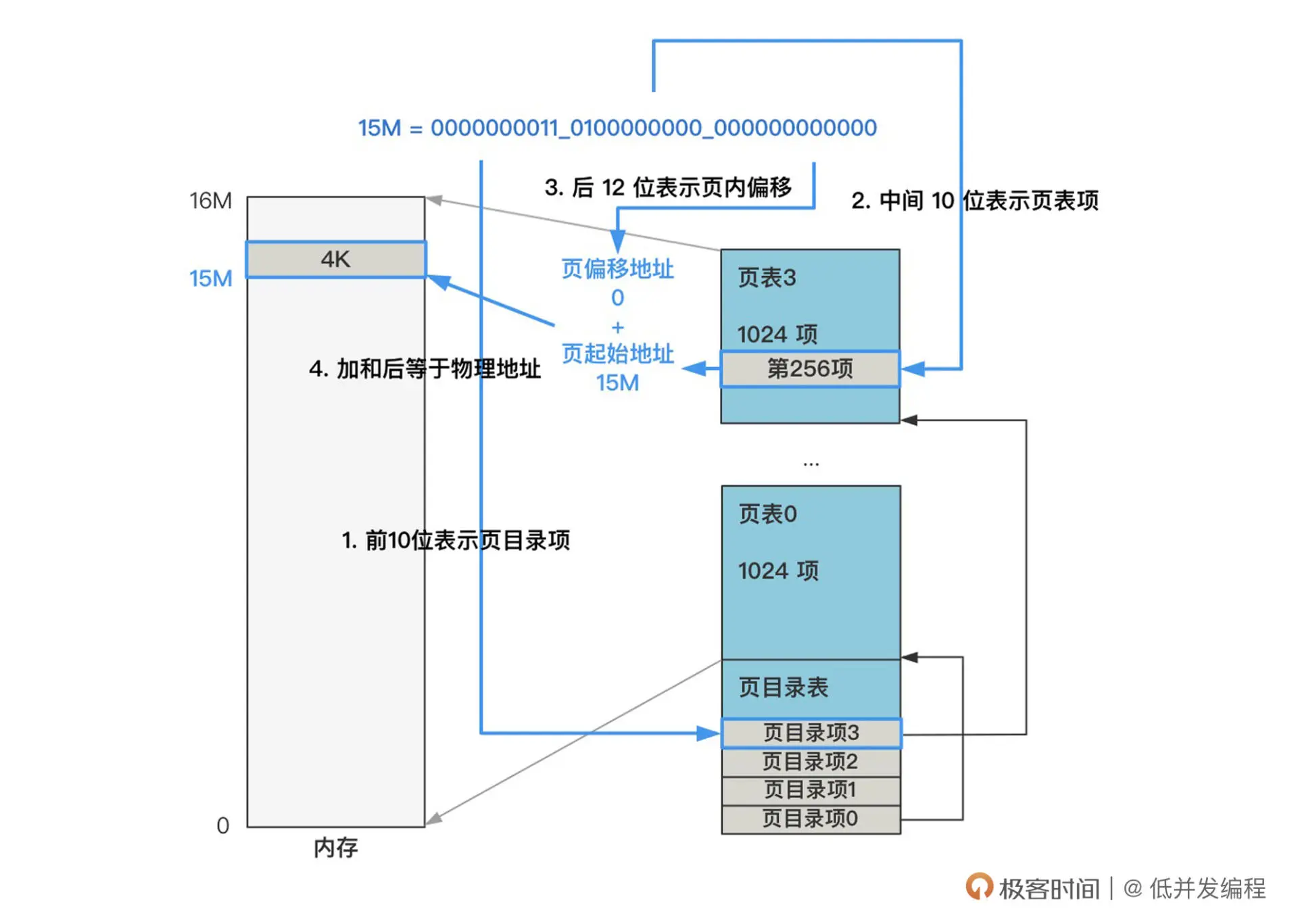
根据闪客在极客空间的例子,如果线性地址是二进制的0000000011_0100000000_000000000000
CPU 在看到我们给出的内存地址后,首先把线性地址被拆分成了这样:高 10 位:中间 10 位:后 12 位
高 10 位负责在页目录表中找到一个页目录项,这个页目录项的值加上中间 10 位拼接后的地址去页表中去寻找一个页表项,这个页表项的值,再加上后 12 位偏移地址,就是最终的物理地址。
这一切的操作,都离不开计算机的一个硬件叫 MMU,中文名叫内存管理单元,有时也叫 PMMU,中文名是分页内存管理单元。这个部件负责的就是把虚拟地址转换为物理地址。
所以整个过程我们不用操心,作为操作系统这个软件层,只需要提供好页目录表和页表,这种页表方案叫做二级页表,第一级叫页目录表 PDE,第二级叫页表 PTE。他们的结构如下:

开启分页机制,并且跳转到 main 函数也在head.s中:
1 | |
开启分页机制:
1 | |
当时 Linux-0.11 认为,总共可以使用的内存不会超过 16M,也即最大地址空间为 0xFFFFFF。
而按照当前的页目录表和页表这种机制,1 个页目录表最多包含 1024 个页目录项(也就是 1024 个页表),1 个页表最多包含 1024 个页表项(也就是 1024 个页),1 页为 4KB(因为有 12 位偏移地址)。
因此,16M 的地址空间可以用 1 个页目录表 + 4 个页表搞定。
4(页表数)* 1024(页表项数) * 4KB(一页大小)= 16MB
所以,上面这段代码就是,将页目录表放在内存地址的最开头 _pg_dir处
之后紧挨着这个页目录表,放置 4 个页表,代码里也有这四个页表的标签项。
1 | |
每个页表(pg0, pg1, pg2, pg3)都位于不同的起始地址,分别是0x1000、0x2000、0x3000和0x4000。在x86架构下,一个页表项通常是32位或64位,即4字节或8字节。对于32位系统,我们通常考虑每个页表项为4字节。
一个页表通常包含1024个页表项,因为每个页表项可以映射到4KB的物理内存。所以,一个页表的大小计算如下:
页表大小 = 页表项大小 × 页表项数量 = 4 字节 × 1024 = 4096 字节 = 4 KB
既然这里有4个页表,那么总的页表空间占用为:
总页表空间 = 4 × 4 KB = 16 KB
所以,这四个页表一起占用了16KB的空间。需要注意的是,这仅是页表本身所占用的空间,而它们共同管理着16MB的物理内存。
最终将页目录表和页表填写好数值,并覆盖整个 16MB 的内存。随后,开启分页机制。
其实就是更改 cr0 寄存器中的一位(31 位),还记得我们开启保护模式么?也是改这个寄存器中的一位的值。
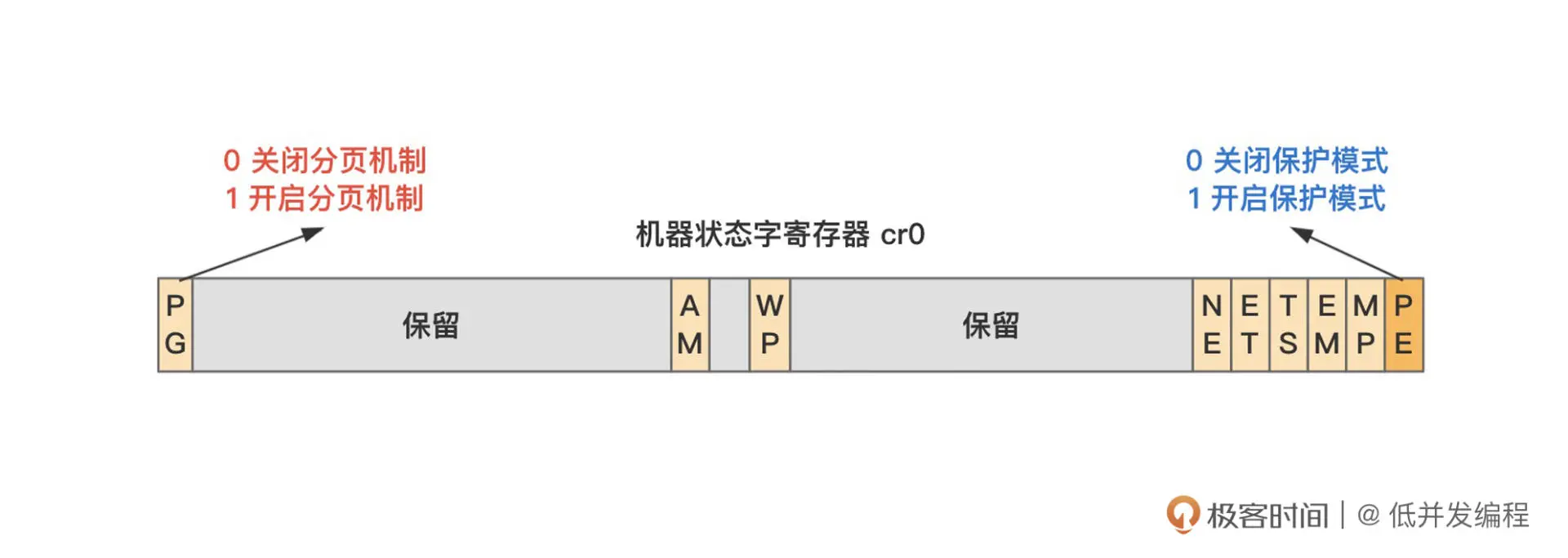
如 idt 和 gdt 一样,我们也需要通过一个寄存器,告诉 CPU 我们把这些页表放在了哪里,具体就是这段代码。
1 | |
我们相当于告诉 cr3 寄存器,0 地址处就是页目录表,再通过页目录表就可以找到所有的页表,也就相当于 让 CPU 知道分页机制的全貌了。
最终内存就变成了这个样子:
跳到主函数
1 | |
push 指令就是压栈,五个 push 指令过去后,栈会变成这个样子。
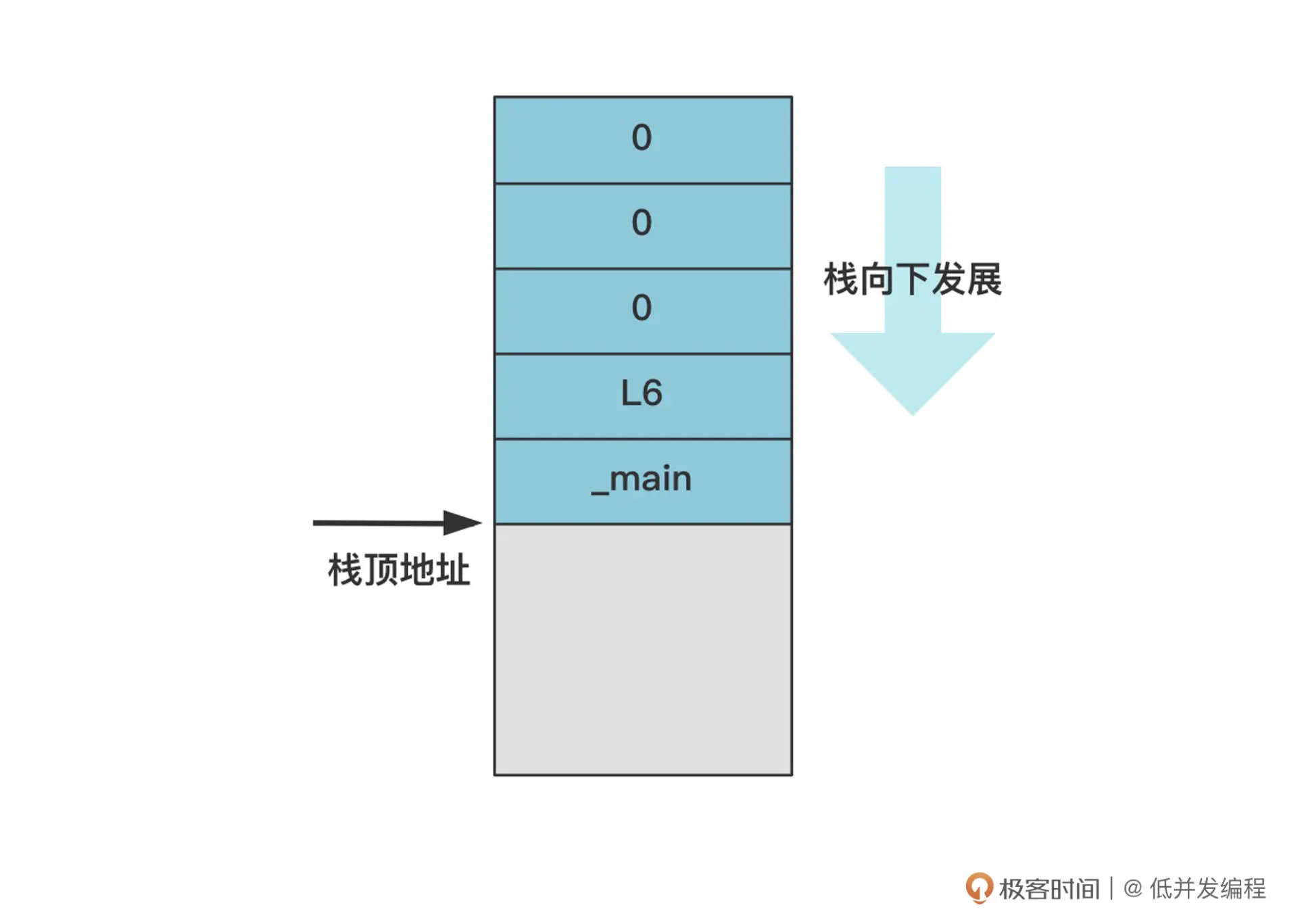
CPU 会把 esp 寄存器(栈顶地址)所指向的内存处的值,赋值给 eip 寄存器,而 cs:eip 就是 CPU 要执行的下一条指令的地址。而此时栈顶刚好是 main.c 里写的 main 函数的内存地址,是我们刚刚特意压入栈的,所以 CPU 就自然而然跳过来了。
除了 main 函数的地址压栈外,其他压入栈中的数据(比如 L6),是 main 函数返回时的跳转地址,但由于在操作系统层面的设计上,main 是绝对不会返回的,所以也就没用了。而其他的三个压栈的 0,本意是作为 main 函数的参数,但实际上似乎也没有用到,所以不必关心。