buffer_init
1
2
3
4
5
6
|
void main(void) {
...
buffer_init(buffer_memory_end);
...
}
|
buffer_memory_end在前已经设置好了,是内存的末尾地址
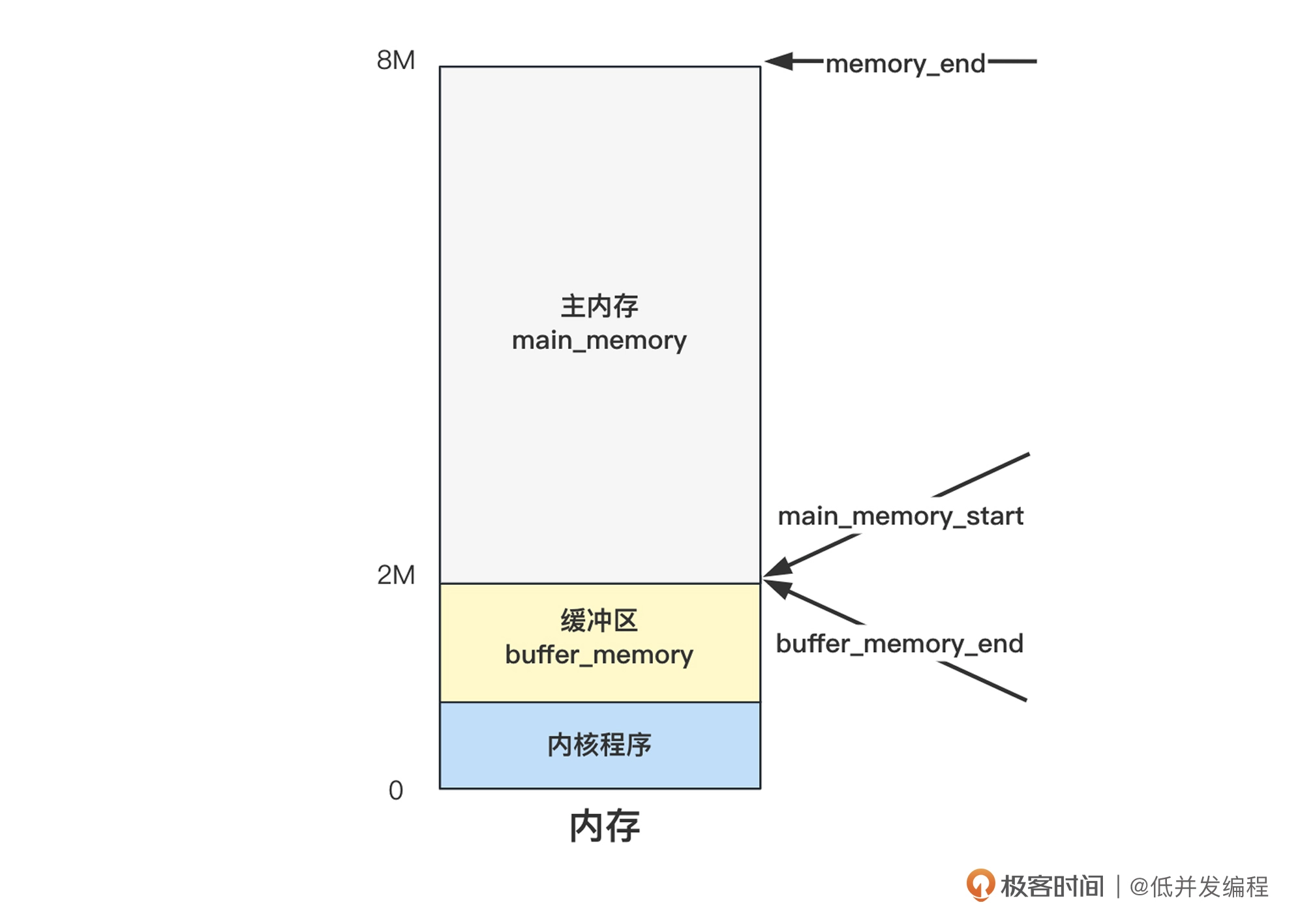
内存管理在前面也已经初始化完成,将内存分页使用mem_map来管理,并将2M以下的部分标记为了已使用
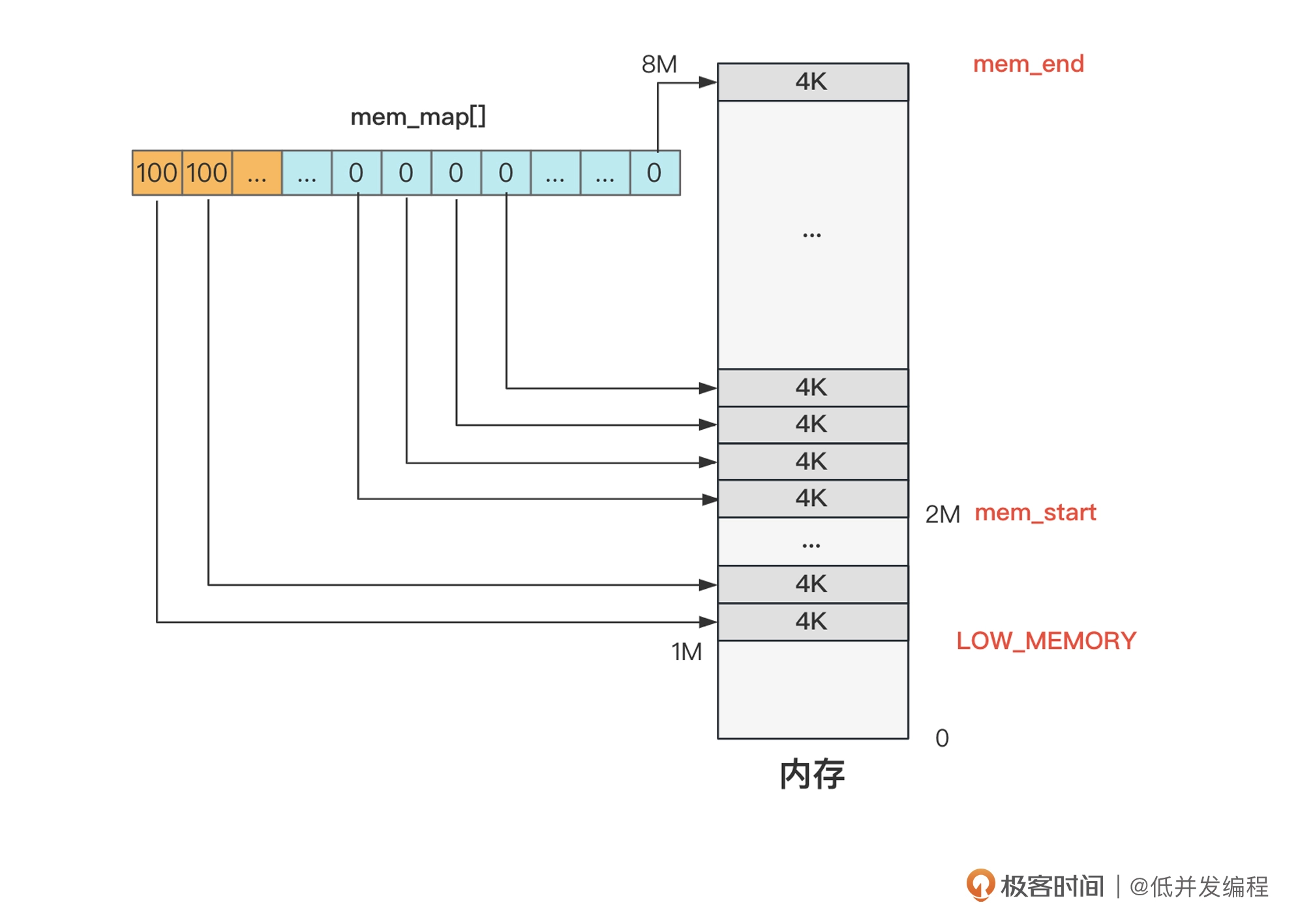
现在剩下2M以下的空间没有管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
extern int end;
struct buffer_head * start_buffer = (struct buffer_head *) &end;
void buffer_init(long buffer_end) {
struct buffer_head * h = start_buffer;
void * b = (void *) buffer_end;
while ( (b -= 1024) >= ((void *) (h+1)) ) {
h->b_dev = 0;
h->b_dirt = 0;
h->b_count = 0;
h->b_lock = 0;
h->b_uptodate = 0;
h->b_wait = NULL;
h->b_next = NULL;
h->b_prev = NULL;
h->b_data = (char *) b;
h->b_prev_free = h-1;
h->b_next_free = h+1;
h++;
}
h--;
free_list = start_buffer;
free_list->b_prev_free = h;
h->b_next_free = free_list;
for (int i=0;i<307;i++)
hash_table[i]=NULL;
}
|
extern int end; 声明了一个外部变量 end,end 变量代表了内存的一个边界,通常在操作系统启动时由链接器(linker)设置,用来指示内核程序代码的结尾。
start_buffer 就等于这个变量的内存地址,内核代码的结尾也就是缓存区的开始。
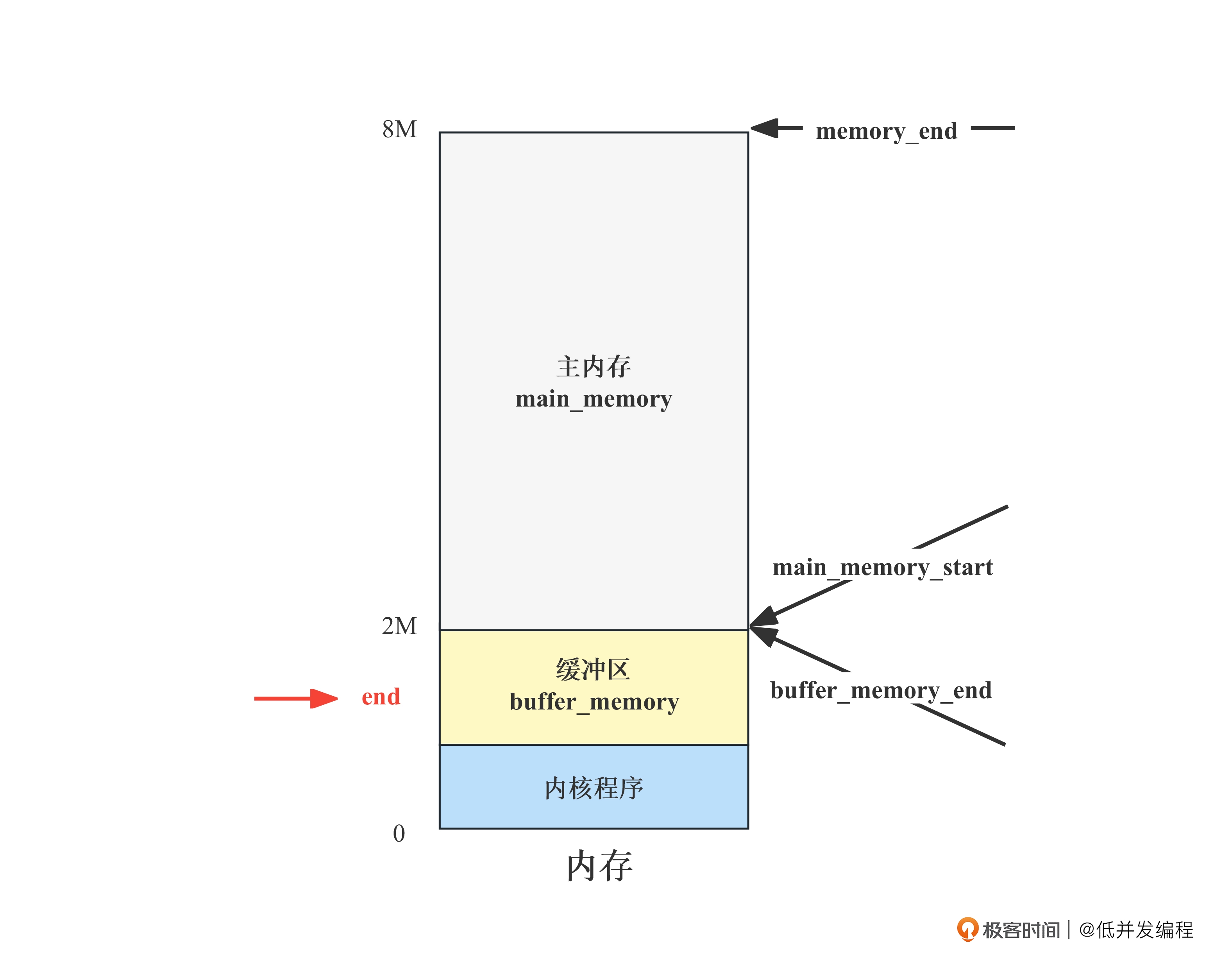
因为我们不知道内核代码会占用多少,所以这个end由链接器来计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| struct buffer_head * h = start_buffer;
void * b = (void *) buffer_end;
while ( (b -= 1024) >= ((void *) (h+1)) ) {
h->b_dev = 0;
h->b_dirt = 0;
h->b_count = 0;
h->b_lock = 0;
h->b_uptodate = 0;
h->b_wait = NULL;
h->b_next = NULL;
h->b_prev = NULL;
h->b_data = (char *) b;
h->b_prev_free = h-1;
h->b_next_free = h+1;
h++;
}
h--;
free_list = start_buffer;
free_list->b_prev_free = h;
h->b_next_free = free_list;
|
h是一个buffer_head的结构体,从名称也可以看出它是缓冲头,其指针值是 start_buffer,刚刚我们计算过了,就是图中的内核代码末端地址 end,也就是缓冲区开头。
b代表缓冲块,指向了缓冲区的结尾。
接着初始化每一个缓冲头,每初始化一个缓冲头,缓冲块向下移动1024,直到间隔一个缓冲头:
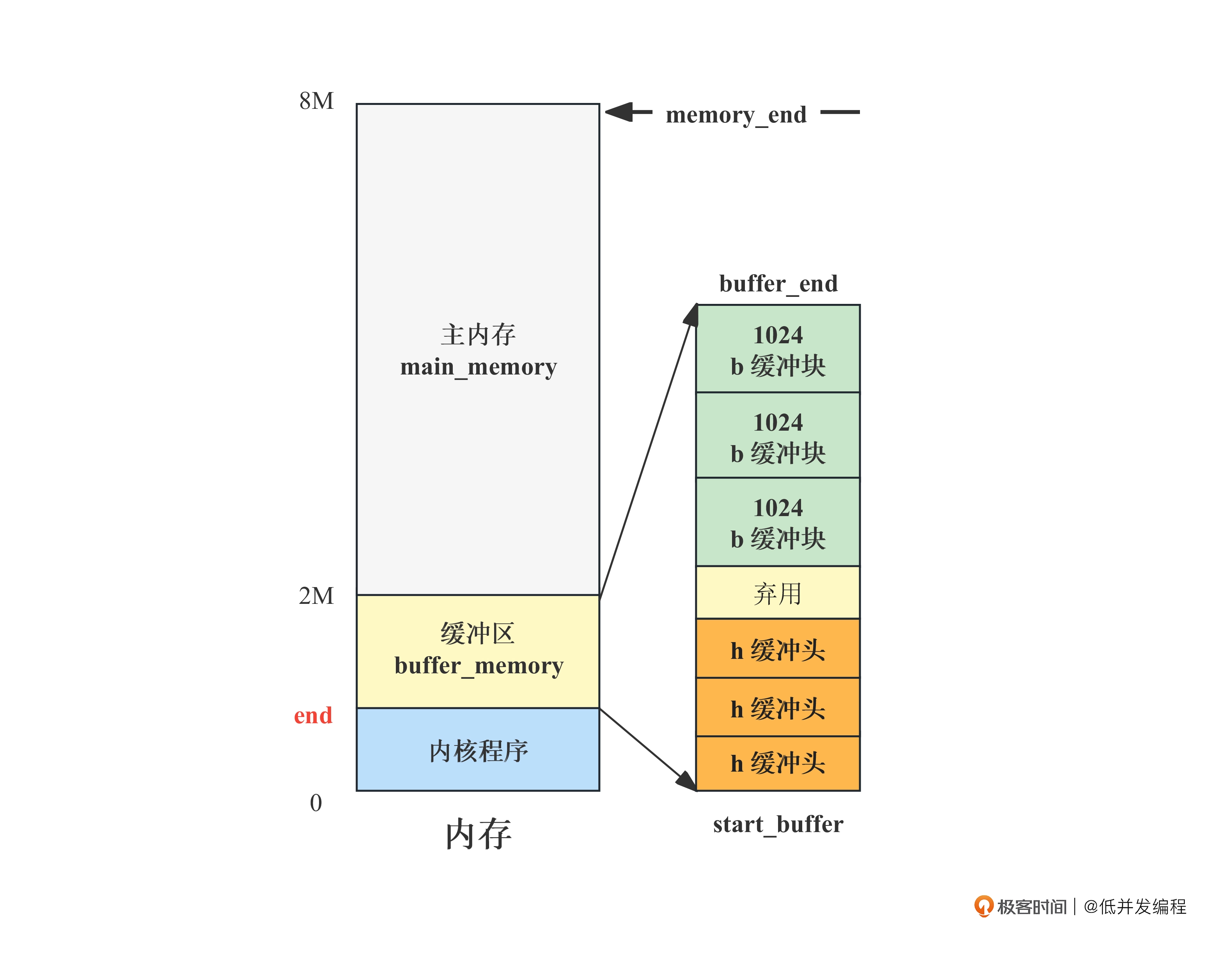
缓冲头和缓冲块是一一对应的,缓冲头的作用就是来寻找缓冲块的。
我们现在先关注缓冲头结构体中的三个指针
1
2
3
| h->b_data = (char *) b;
h->b_prev_free = h-1;
h->b_next_free = h+1;
|
b_data指向缓冲块的地址b_prev_free指向上一个缓冲头b_next_free指向下一个缓冲头
这是一个明显的双链表结构,在初始化完成所有的缓冲头后,将头尾节点连接到一起
1
2
3
4
| h--;
free_list = start_buffer;
free_list->b_prev_free = h;
h->b_next_free = free_list;
|
最终缓冲区就变成了这样:
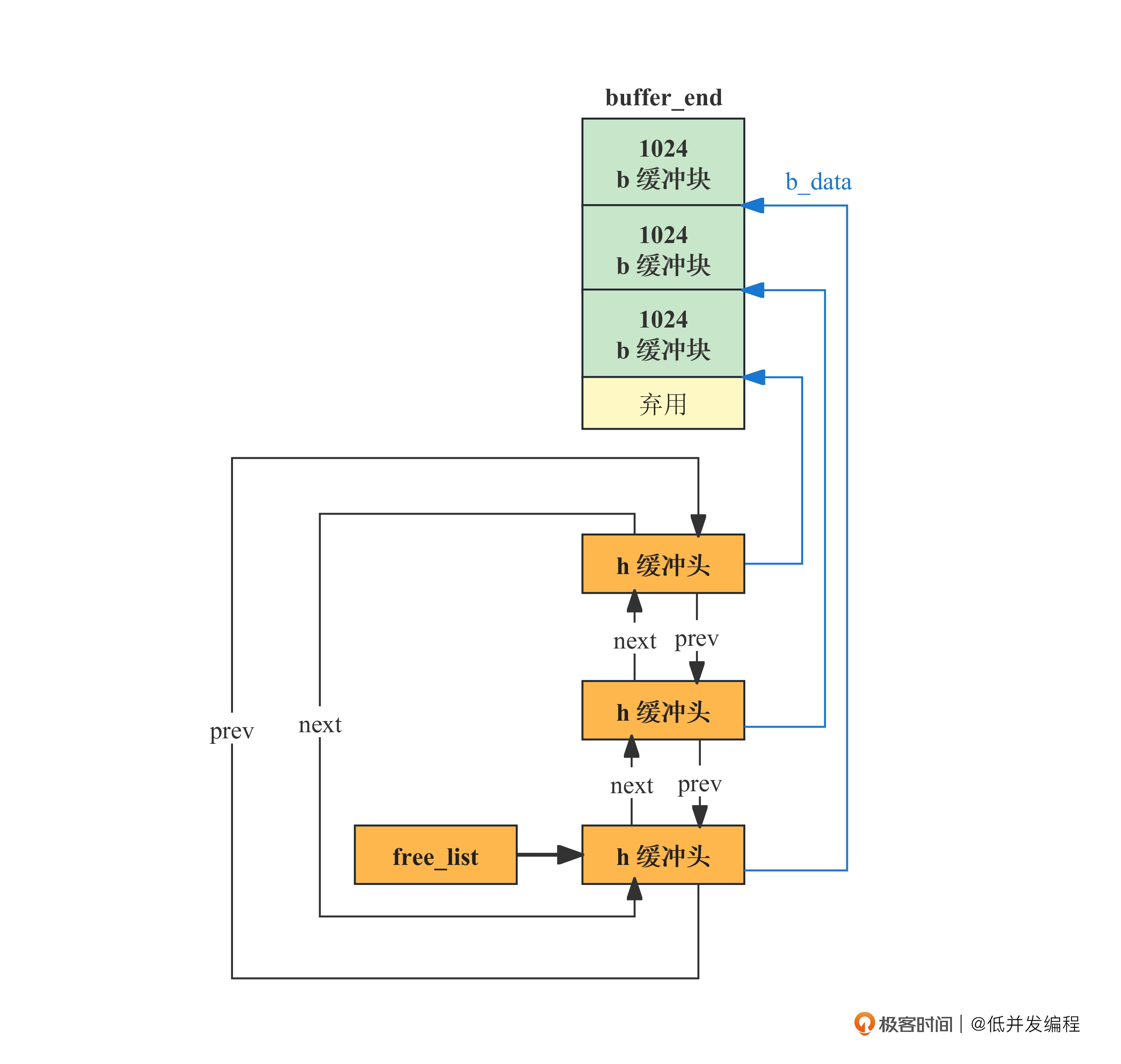
free_list 指向了缓冲头双向链表的第一个结构,然后就可以顺着这个结构,从双向链表中遍历到任何一个缓冲头结构了,而通过缓冲头又可以找到这个缓冲头对应的缓冲块。
简单说,缓冲头就是具体缓冲块的管理结构,而 free_list 开头的双向链表又是缓冲头的管理结构,整个管理体系就这样建立起来了。
现在,从 free_list 开始遍历,就可以找到这里的所有内容了。
LRU算法
1
2
3
4
5
6
|
void buffer_init(long buffer_end) {
...
for (i=0;i<307;i++)
hash_table[i]=NULL;
}
|
最后,初始化了一个大小为307的哈希表,哈希表+双向链表就构成了LRU算法。
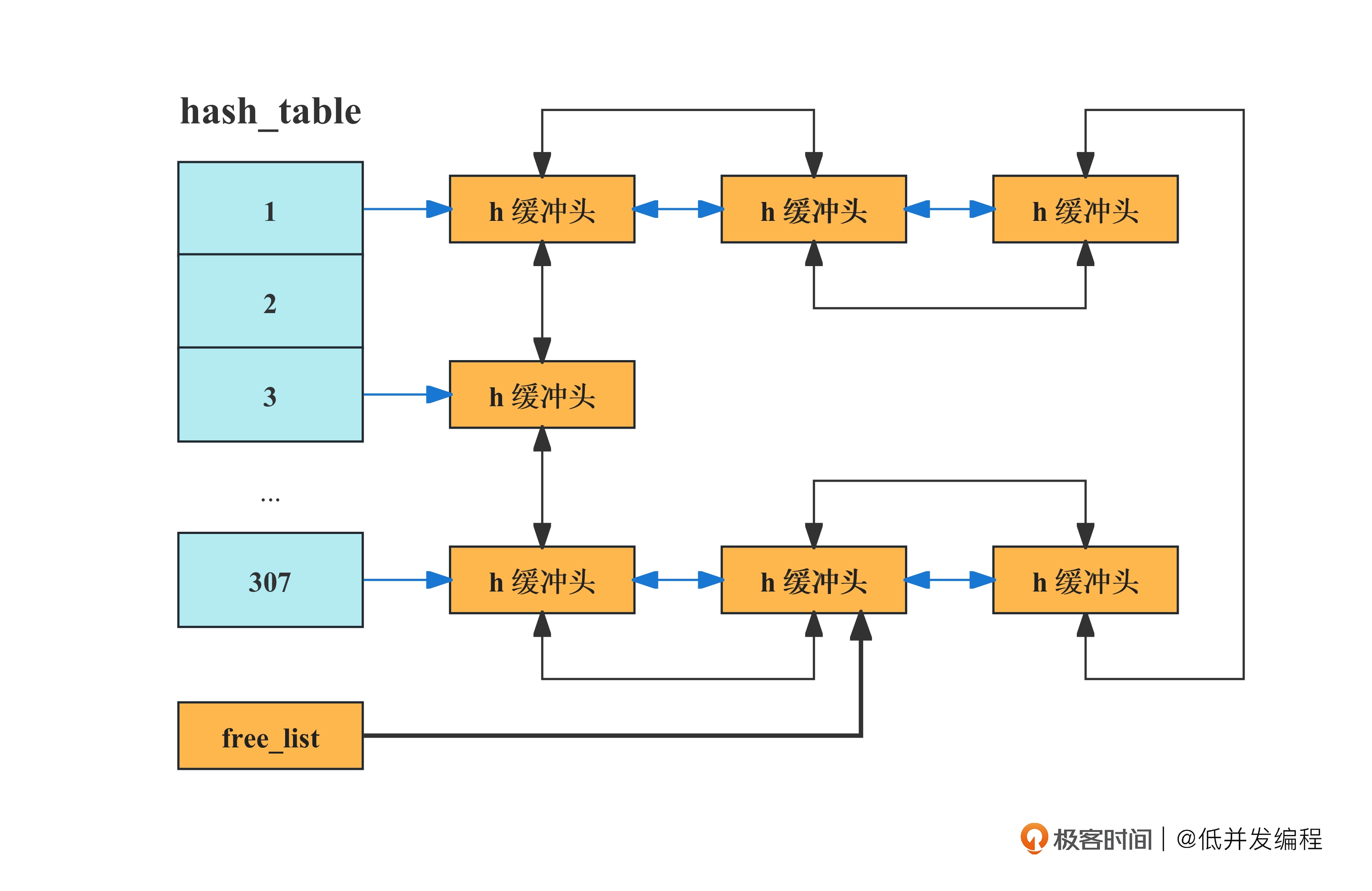
缓冲区(缓存)使用LRU(Least Recently Used)算法时,会优先淘汰那些“最久未被访问”的数据,以便腾出空间来存储新的数据。这种策略基于一个假设:数据越久未被访问,未来被访问的可能性越小。因此,我们可以把最不常用的数据项移出缓存,让新的数据占据这个位置。
LRU算法的原理
LRU算法的基本原理是:
- 当访问一个数据项时,把它标记为最近使用。
- 当缓存满了,需要移出一项来插入新数据时,移出缓存中最久未使用的数据项。
实现这一点通常可以使用一个双向链表和哈希表的组合: